Implementing Natural Language Processing in Python, ML.NET, Apache Spark and Azure Cognitive Services

Say hello to my co-writer today, Atticus Jack
This article is a continuation of a series in which I explore different implementations of machine learning tasks across different programming ecosystems. Today, I'm going over ML.NET, Python, Apache Spark, and Azure Cognitive Services. The task is natural language processing - and specifically sentiment analysis. While I cover Python and C# ecosystems, Atticus will be diving into the Java implementation with Apache Spark.
What is Natural Language Processing?
Natural language processing at its core is simply a method for a computer to understand human language. We've been doing this in chat bots for ages using if/then trees and switches. However, in recent years natural language processing has become more sophisticated. Some natural language processing uses statistical analysis on phrases, while other use neural networks to analyze and process words and sentences.
Natural language processing has come a long way and it's used everywhere from predective text to speech to text not to mention the newer more sophisticated chat bots that exist now.
But the ecosystems that exist to create a natural language process vary quite a lot.
We'll be providing commentary and opinions along the way as well, just to warn you.
Explaining the data
The data very simple. It's a tab separated file with reviews as a column and a column to record the tone of the text, whether it's 0 for negative or 1 for positive. This is the standard set of data to play with for sentiment analysis, which is what we're going to do.
The Azure Cognitive Services does not use this data set, although it certainly could start making predictions right away. The reason we don't is that after a certain number of predictions Azure will start to accrue charges. I opted to stay well within the boundaries of the free tier.
Take a look at the data:
Libraries
Each tool has its own set of libraries to manage this task. They all more or less split up the necessary tasks into classes and namespaces.
Python
With Python, as usual, we have the three main libraries needed to perform machine learning tasks.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Further down the process we're also importing some classes and features from the Python language processing modules. Regular Expressions (re) and the Natural Language Took Kit (nltk).
import re
import nltk
ML.NET
ML.NET has the usual suspects and also a few libraries that are specific to text prepartion and consumption. The system libraries are purely for reading in the data from a file and managing collections. The Microsoft ML libraries are the interesting ones. Probably the using that really stands out is the static Microsoft.ML.DataOperationsCatalog. This library is basically responsible for loading our data and performing the train and test split. If you attempt to use this library without the static keyword then the compiler will provide an error and suggest a resolution. Pretty nice, right?
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Data;
using static Microsoft.ML.DataOperationsCatalog;
using Microsoft.ML.Trainers;
using Microsoft.ML.Transforms.Text;
Apache Spark
Apache Spark requires a fair few classes from two separate Libraries. The Apache Spark library provide a base for machine learning while the John Snow Labs library adds natural language processing capabilities. (Note as of writing this article John Snow Labs NLP library only work with Java 8)
import com.johnsnowlabs.nlp.DocumentAssembler;
import com.johnsnowlabs.nlp.LightPipeline;
import com.johnsnowlabs.nlp.SparkNLP;
import com.johnsnowlabs.nlp.annotators.Tokenizer;
import com.johnsnowlabs.nlp.annotators.sda.vivekn.ViveknSentimentApproach;
import com.johnsnowlabs.nlp.pretrained.PretrainedPipeline;
import com.mj.machine.learning.spark.entity.NaturalLanguageProcessorSentiment;
import lombok.extern.slf4j.Slf4j;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.ml.Pipeline;
import org.apache.spark.ml.PipelineModel;
import org.apache.spark.ml.PipelineStage;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.springframework.stereotype.Service;
Azure Cognitive Services
Azure Cognitive Services requires the fewest libraries which makes sense considering we'll be offloading all of the model building to an Azure service.
using Azure;
using System;
using System.Globalization;
using Azure.AI.TextAnalytics;
Setup
Each of these ecosystems requires varying degrees of work to get setup.
For Apache Spark, feel free to fire up your favorite code editor, install Java 8, and try to get this running: See the code on Github.
For Python and ML.NET I've set up a couple of Binder projects for you to try them out.
Python
Surprisingly, the Python process is a little more hands on during the featurizing of the text. Here we need to add a parameter while loading in the data quoting = 3 which tells Python to ignore quotes while looking at the text.
Next, while iterating through the reviews, we need to remove "stopwords" which are described as articles (the, this, that, etc) and pronouns and the like. These words are removed since they don't carry any particular meaning that we need to interpret to get the sentiment. We are also using a class to change all words into a base type. So "loved" is changed to "love" for example. This allows us to reduce the size of the set of words without removing sentiment meaning. So, in this process even though "loved" is past tense it still conveys the same positive context as "love" and therefore there is little benefit in including both words in our set of words to be analyzed.
One interesting thing in this step is that we have to explicitly include the word 'not'. 'Not' is considered a stop word and would be removed - but it conveys sentiment so it should be included. It's an interesting detail in the Python implementation that more or less implies you need to pay close attention to the process here.
dataset = pd.read_csv('Restaurant_Reviews.tsv', delimiter = '\t', quoting = 3)
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
corpus = []
for i in range(0, 1000):
review = re.sub('[^a-zA-Z]', ' ', dataset['Review'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
all_stopwords = stopwords.words('english')
all_stopwords.remove('not')
review = [ps.stem(word) for word in review if not word in set(all_stopwords)]
review = ' '.join(review)
corpus.append(review)
Now that we've created a set of reviews and processed them a bit we process them a bit more by creating something called a bag of words model. A bag of words model is a way to measure the importance of a word by counting how frequently it's used, among other things - I believe there is some vectorization also occuring - so measuring the proximity of words with other words.
Here we also recognize that there is little value in some words, including most nouns, so we try to exclude them by putting a limit on the maximum number of features included in the model. In this way we hope to exclude those words that don't carry sentiment. So they don't tell us if the overall review is good or bad. There is no guarantee that we're excluding all of these words - we're only setting an upper bound on words included and hoping that the words excluded are all of the type we wish to exclude.
This process taken as a whole is called tokenization.
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features = 1500)
X = cv.fit_transform(corpus).toarray()
y = dataset.iloc[:, -1].values
Next we do the usual process of splitting into training and test sets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
From here we are ready to create an ML model.
ML.NET
For once, ML.NET requires less set up than python.
Here we establish our classes. The first class is a representation of each row in our dataset. The second class represents the output from a prediction.
public class SentimentData
{
[LoadColumn(0)]
public string SentimentText;
[LoadColumn(1), ColumnName("Label")]
public bool Sentiment;
}
public class SentimentPrediction : SentimentData
{
[ColumnName("PredictedLabel")]
public bool Prediction { get; set; }
public float Probability { get; set; }
public float Score { get; set; }
}
Next we can load the data and split into our training and test sets. We did not have to think at all about the content of the text for this step, unlike Python which required a fair amount more setup. However, we get better insight into how the process works from Python. If you've followed my other articles you might be amused by this as usually it's ML.NET that provides insight into the process whereas everything 'just works' in Python. This is a fun turnabout.
MLContext context = new MLContext();
IDataView dataView = mlContext.Data.LoadFromTextFile<SentimentData>(".\\Restaurant_Reviews.tsv", hasHeader: true);
TrainTestData splitDataView = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2);
Apache Spark
Apache Spark only requires importing the libraries to use them. For this project Spring Boot was used as a fast way to get the libraries into a container where they could be run. Again for the sake of simplicity webservice endpoints are used to interact with Apache Spark and John Snow Labs Natural Language Processor(NLP).
Azure Cognitive Services
Azure Cognitive Services has extremely simple setup - most of which occurs on the Azure Portal.
You need to create a Text Analytics resource and grab a key and the endpoint.
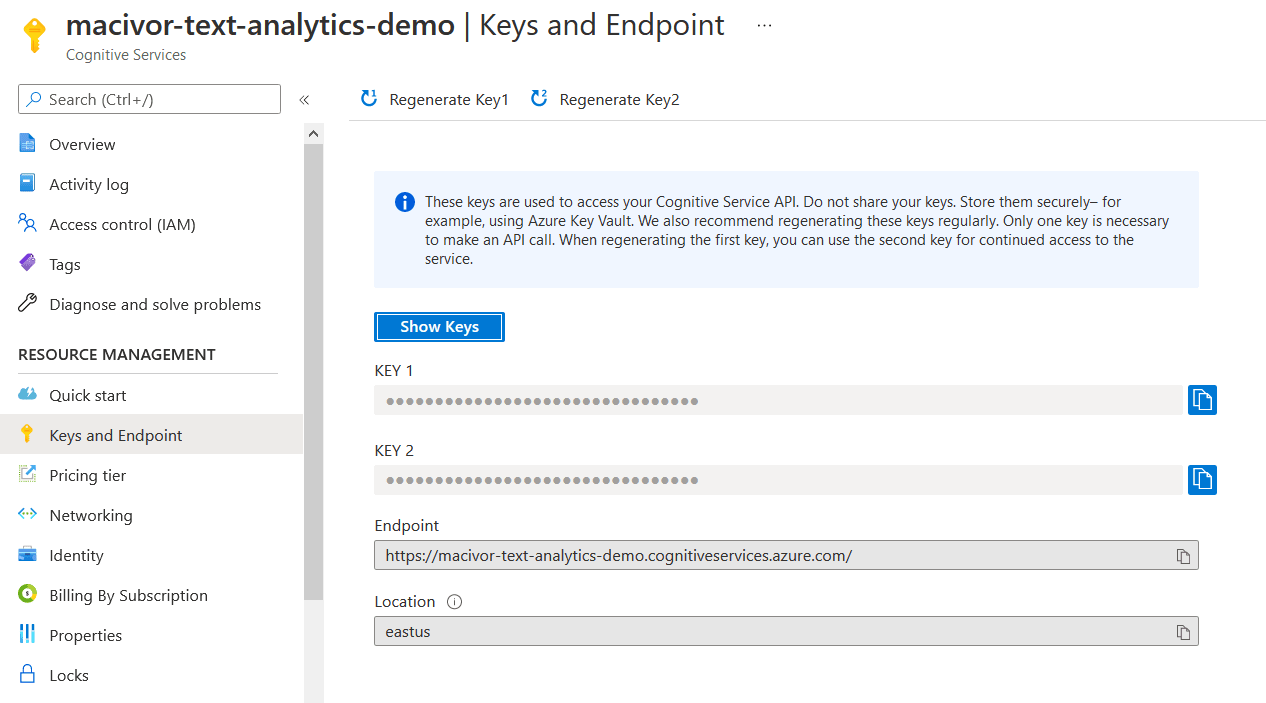
And then in your code you create a client from those resources. That's it! But there are tradeoffs to be explored.
private static readonly AzureKeyCredential credentials = new AzureKeyCredential("<your key>");
private static readonly Uri endpoint = new Uri("<your endpoint>");
var client = new TextAnalyticsClient(endpoint, credentials);
Establishing a Pipeline and Creating a Model
Typically this is the easiest step across all platforms. Python, at least, has something new for this blog series so I'll be diving into that a little more deeply.
Python
The Python code is deceptively simple. It is expressed in only three lines of code.
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
It's using something called Naive Bayes Theorum to create a model to predict results. The Naive Bayes Theorum suggests that a features (in this case words) are mutually independent and that classification is linear. So for example, for our words we're measuring how often they appear in the document body (so all reviews taken as a whole) and which sentiment prevails for those appearances. (Are they aggregate positive or negative.) That the classification is linear means that we can divide the features to be classified with a simple line. In practice, the independence of the features is questionable - and yet the Naive Bayes theorum still manages to perform relatively well.
ML.NET
ML.NET abstracts a lot of the tokenization out of the process for us by providing a binary classification trainer. All we need to do is declare what our features are and the trainer takes care of the rest of the work. This worked well for this example, but for more custom sentiment analysis you might need to dive into the guts of pipeline creation to control and refine the tokenization process.
var estimator = mlContext.Transforms.Text.FeaturizeText(outputColumnName: "Features", inputColumnName: nameof(SentimentData.SentimentText))
.Append(mlContext.BinaryClassification.Trainers.SdcaLogisticRegression(labelColumnName: "Label", featureColumnName: "Features"));
var model = estimator.Fit(splitTrainSet);
Apache Spark
Loading the data to train a pipeline is more hands on using Apache Spark. First you need to create a dataset, for this I created an entity that contained two strings, the sentence and its sentiment. These entities get passed into the application via a web service call and then loaded into a dataset like so. (note: NaturalLanguageProcessorSentiment is the entity contining the two strings.)
Dataset<Row> inputDataset = sparkSession.createDataFrame(sentimentData, NaturalLanguageProcessorSentiment.class);
Next a pipeline needs to be generated to process dataset. This effectivly tells the pipeline how to read and interpret the data being passed to it.
DocumentAssembler documentAssembler = new DocumentAssembler();
documentAssembler.setInputCol("sentence");
documentAssembler.setOutputCol("document");
String[] tokenizerInputCols = { "document" };
Tokenizer tokenizer = new Tokenizer();
tokenizer.setInputCols(tokenizerInputCols);
tokenizer.setOutputCol("token");
String[] sentimentInputCols = { "document", "token" };
ViveknSentimentApproach sentimentApproach = new ViveknSentimentApproach();
sentimentApproach.setInputCols(sentimentInputCols);
sentimentApproach.setOutputCol("sentiment");
sentimentApproach.setSentimentCol("sentiment");
sentimentApproach.setCorpusPrune(0);
Pipeline pipeline = new Pipeline();
pipeline.setStages(new PipelineStage[]{ documentAssembler, tokenizer, sentimentApproach });
Finally, the data can be fit to the pipeline, and a new pipeline can be created.
PipelineModel pipelineModel = pipeline.fit(inputDataset);
LightPipeline lightPipeline = new LightPipeline(pipelineModel, false);
Azure Cognitive Services
Due to the nature of Azure Cognitive Services there is nothing to do here. The model training has already been completed and the model is waiting for you to send it documents to be analyzed. This has the obvious drawback of you having no idea whether the model provided will perfectly fit your needs. However, for most sentiment analysis jobs this works just fine. If your goal is to figure out if a posted comment is positive or negative you will never have to reach further than this.
Predictions, Ease and Accuracy
Finally, which of these processes actually works the best? This is a tough question since each of these processes can be refined to fit a specific business case. Certainly how the ease of implementation is a factor - and accuracy can be corrected with larger models and tweaks to the pipeline and tokenization process.
Python
With Python we can run our tests and get an analysis of accuracy with this code:
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
accuracy_score(y_test, y_pred)

We discover that the accuracy score for the Python code is 73% - which is okay, not great. There are certainly ways to improve it by improving the tokenizatin process - but it is strange to see Python not absolutely ruling with straight out of the box methods. When we were exploring regression we saw that usually Python required very little configuration to provide spectacular results.
ML.NET
Meanwhile, the ML.NET code does a somewhat better job for us here with an accuracy score of 83%.
Console.WriteLine("=============== Evaluating Model accuracy with Test data===============");
IDataView predictions = model.Transform(splitTestSet);
CalibratedBinaryClassificationMetrics metrics = mlContext.BinaryClassification.Evaluate(predictions, "Label");
Console.WriteLine();
Console.WriteLine("Model quality metrics evaluation");
Console.WriteLine("--------------------------------");
Console.WriteLine($"Accuracy: {metrics.Accuracy:P2}");
Console.WriteLine("=============== End of model evaluation ===============");
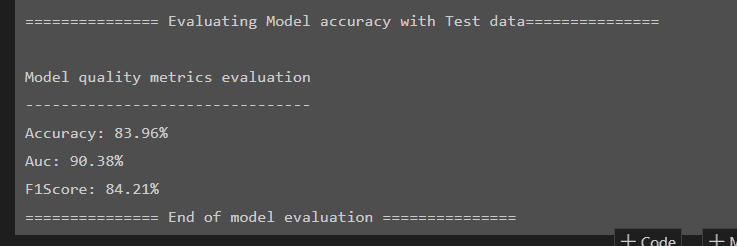
Usually, our ML.NET code does not do better than Python so this is a surprise. It seems that the out of the box optimizations (and likely the selection of the correct trainer) helped a lot. Usually the selection of a trainer is difficult in ML.NET as there are many choices available - but in this case the ML.NET documentation led us to the most suitable trainer straight away, saving us from the usual trial and error approach to selection.
Apache Spark
The only finicky thing about using either a pre-generated pipeline, or a pipeline you train yourself is the way you have to pass data into the pipeline. The results you get back is easy to parse through. Apache Spark passes your data back to you with the same keys you definied for it to use while createing your pipeline.
public Map<String, String> analyzeSentimentOfSentencesWithGeneratedPipeline(
List<String> sentencesToBeAnalyzed)
{
Map<String, String> returnValue;
ArrayList<String> sentenceArrayList;
List<Map<String, List<String>>> analysisList;
sentenceArrayList = new ArrayList<>(sentencesToBeAnalyzed);
analysisList = generatedSentimentPipeline.annotateJava(sentenceArrayList);
returnValue = new LinkedHashMap<>();
analysisList.forEach(analysis -> {
String sentence = analysis.get("document").get(0);
String sentiment = analysis.get("sentiment").get(0);
returnValue.put(sentence, sentiment);
});
return returnValue;
}
Azure Cognitive Services
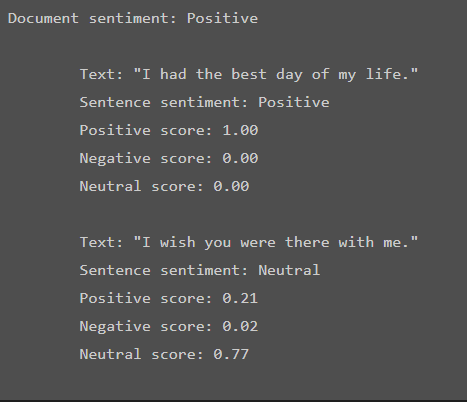
The result from Azure Coginitive Services is a bit more nuanced. Where normally we are evaluating all of the reviews in the document, that is unnecessary (and even expensive) with Azure Cognitive Services. Instead we can feed it one review at a time and we get back an analysis of that review, positive or negative - as well as a breakdown of the score of each sentence.
string inputText = "I had the best day of my life. I wish you were there with me.";
DocumentSentiment documentSentiment = client.AnalyzeSentiment(inputText);
Console.WriteLine($"Document sentiment: {documentSentiment.Sentiment}\n");
foreach (var sentence in documentSentiment.Sentences)
{
Console.WriteLine($"\tText: \"{sentence.Text}\"");
Console.WriteLine($"\tSentence sentiment: {sentence.Sentiment}");
Console.WriteLine($"\tPositive score: {sentence.ConfidenceScores.Positive:0.00}");
Console.WriteLine($"\tNegative score: {sentence.ConfidenceScores.Negative:0.00}");
Console.WriteLine($"\tNeutral score: {sentence.ConfidenceScores.Neutral:0.00}\n");
}
Thoughts
James
For me, ML.NET does a great job and for the cost and ease of setup is a great choice for .NET shops looking for easy sentiment analysis. However, Azure Cognitive Services really appeals to me with the ease of setup and the sentence analysis. I like how easy it is to dive in and start making decisions. It definitely would come down to the priority of the business, cost or speed.
If speed is the priority then Azure Cognitive Services is the best choice. But it needs to be understood that this dependency has a cost. It's not a terrible expense - but it needs to be accounted for and tracked.
If cost is the priority then ML.NET works very well - but considerable thought needs to go into how to deploy and maintain your model.
I continue to be impressed with the Python way - but I'd rather not be burdened with configuring the bag of words model and tokenizing the document myself. Even though Python provides wonderful tooling to refine the process - it's still not as easy as ML.NET.
Atticus
Apache Spark did a good job of analyzing the data, the most confusing part is wrapping your head around how to properly setup the pipelines. I spent several hours reading the documentation and still have to get caught back up after any amount of time out of the code. This complexity is great if you have an equally complex pipeline you need to train, it works against you if you need a model right now.
The only other issue with the Apache Spark NLP is that the NLP libraries currently only support Java 8.